Webpage Meta Scraper
Extract Page Titles, Descriptions and Keywords
Webpage Meta Scraper
- Included with ScrapeBox
- Multi-Threaded Connections
- Adjustable Connections
- Proxy Support
- Automator Support
- Extract Webpage Titles
- Extract Webpage Descriptions
- Extract Websites keywords
- Excel and txt data export
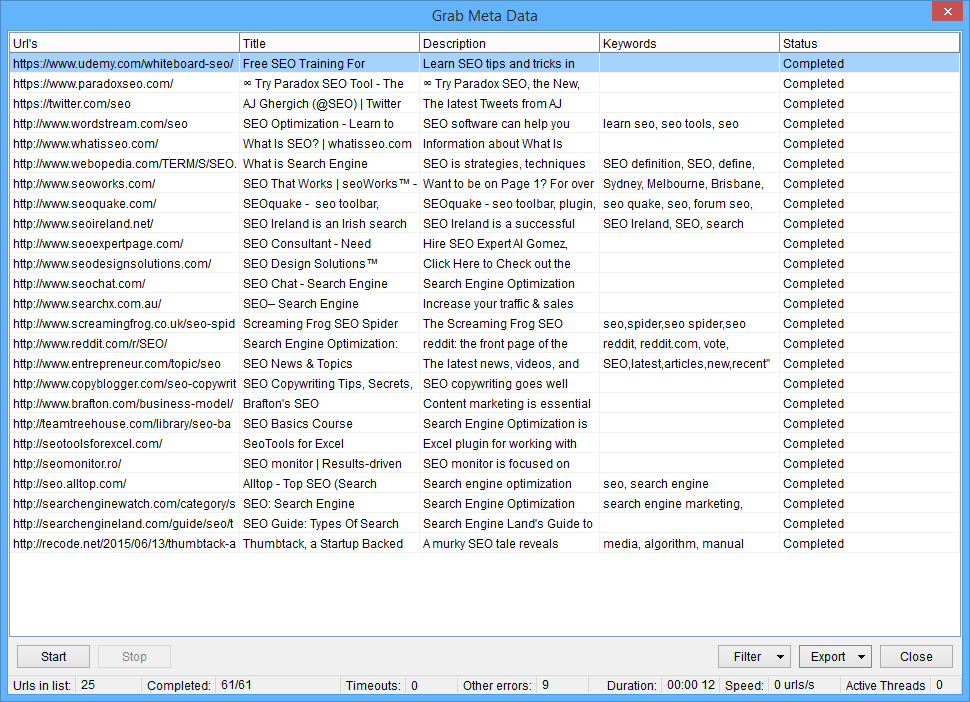
ScrapeBox offers a Meta Grabber feature, this enables you to load a list of urls and extract the page Titles, Descriptions and Keywords for every URL in the list. This feature is multi-threaded and can harvest the data from hundreds of pages per minute, once finished you can filter the data by removing urls with errors, or for example urls without meta keywords. You can then export the data to .txt file, or to .csv or .xls for use in Excel. When exporting you also have the option to export URL’s, Titles, Descriptions, Keywords or any combination of one or more of these fields.
Being able to harvest meta information is great for competitor research, or auditing your own websites Titles and Descriptions to ensure they are optimal for your webpages as many CMS platforms auto-generate these fields. The page Title and Description are extremely important page attributes, because search engines display this information in the search result pages. So poorly created Titles and Descriptions can impact click through’s from the engines. This feature is also useful to identify spammy pages that have been “stuffed” with hundreds of Meta Keywords or long Meta Descriptions that was common practice in SEO many years ago but now may be harming your rankings.
Also the Meta harvester is ideal to use to harvest all the keywords for your competitors pages, then transfer these to the ScrapeBox keyword scraper to get further keyword suggestions from Google Suggest, Shopping.com, YouTube etc for further analysis and promotion.
To use simply harvest URL’s for your chosen keywords or load URL’s from a file, then use the “Grab” button on the harvester and select “Grab meta info from harvested URL list”
Meta Scraper Tutorial
View our video tutorial showing the Webpage Meta Scraper in action. This feature is included with ScrapeBox, and is also compatible with our Automator Plugin.
We have hundreds of video tutorials for ScrapeBox.
View YouTube Channel